forge-docs
Performance Testing Summary (ECS Native + k6)
Executive Summary
We executed a structured performance test plan against Forge deployed on AWS ECS (GraalVM native) using k6 load generation from inside the same VPC. The key result is that Forge demonstrated repeatable throughput and predictable tail latency at scale, with clear saturation signals and clean recovery via horizontal scaling.
Across the baseline and tuned scaling envelopes:
- ~56 req/s @ 50 VUs (baseline)
- ~111 req/s @ 100 VUs (scaling step)
- ~222 req/s @ 200 VUs (after scaling from 1 → 2 ECS tasks, steady-state Runs 3–5)
Throughout these steps, aggregate HTTP medians remained in the single-digit millisecond range. This is the strongest evidence that the internal service tier is not the bottleneck for this workload at these concurrency levels and that the services recover predictably under horizontal scaling.
What we can confidently say:
- Repeatability: Run-to-run variation in the steady-state envelopes is very small (sub-1% at the relevant steps).
- Scalability with saturation + recovery: Scaling remained near-linear until the single-task saturation point was approached. At 200 VUs, the 1-task topology began approaching saturation at ~190 req/s (Runs 1–2); scaling to 2 ECS tasks restored low-latency steady state at ~222 req/s (Runs 3–5).
- Stateless scaling: The clean 1 → 2 task recovery behaviour is consistent with a stateless service architecture.
- GraalVM native runtime: The ECS runs used GraalVM native images throughout. This contributed to maintaining stable low-latency behaviour at intentionally small task sizes.
- Primary tail drivers (not fully isolated): Authentication-heavy flows dominate observed tail latency in the mixed workload, with Cognito and related auth-path infrastructure contributing materially to aggregate p95/p99 behaviour. Attribution is not fully isolated (auth path also includes WAF/ALB/network and seeded-user concurrency effects).
- Small-footprint efficiency: These results were achieved on intentionally minimal infrastructure sizing (0.25 vCPU / 512 MiB
ECS tasks and a
t3.micro-class database), validating a high throughput-per-resource operating point before any production-scale vertical tuning. - What this does not mean: These figures should not be interpreted as universal “application capacity” numbers. Forge is a platform foundation; production throughput will depend on workload mix, enabled domain services, infrastructure profile, caching strategy, and external integrations in a given deployment.
For the detailed results and math, see the phase write-ups in this directory, especially Phase 4:
- Phase 4 @ 200 VUs envelope:
performance/phase_4/ECS_NATIVE_BASELINE_MIX_200VU_LOAD3M_ENVELOPE.md - Phase 4 @ 100 VUs envelope:
performance/phase_4/ECS_NATIVE_BASELINE_MIX_100VU_LOAD3M_ENVELOPE.md - Baseline (Phase 2) envelope @ 50 VUs:
performance/phase_2/ECS_NATIVE_BASELINE_MIX_50VU_LOAD3M_ENVELOPE.md
Phase 4: key graphs
These were captured during the Phase 4 runs and provide quick “shape of system” evidence alongside the envelope doc.
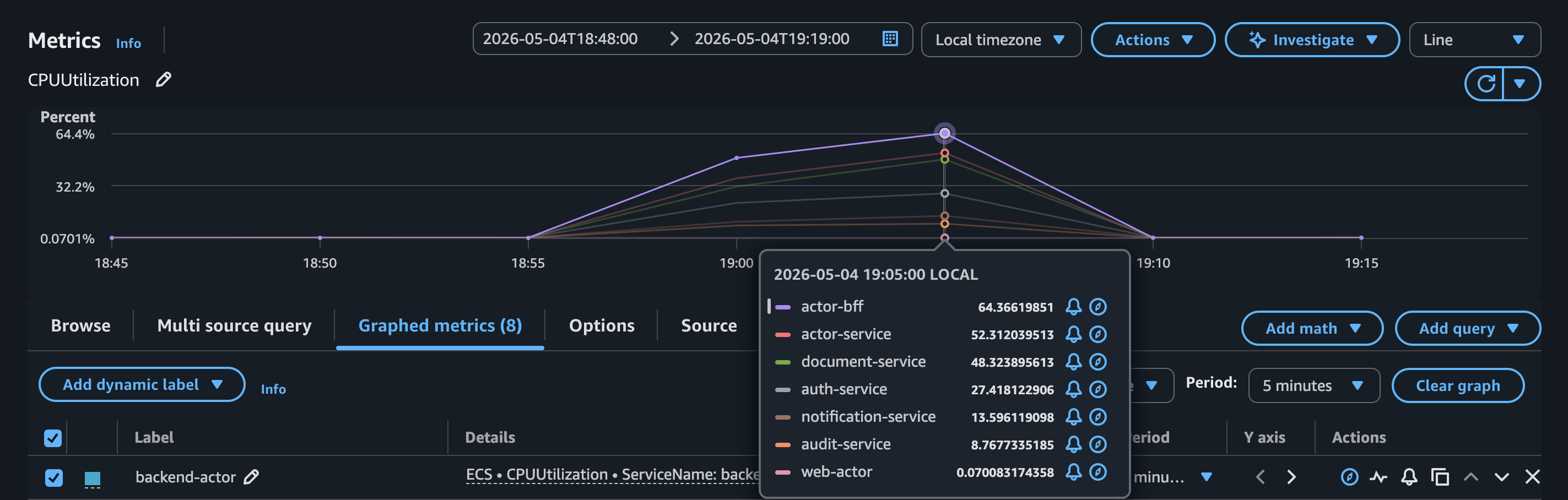
- CPU utilization across the micro-sized (0.25 vCPU) ECS services during the Phase 4 run (200 VUs dataset).
- RDS PostgreSQL (
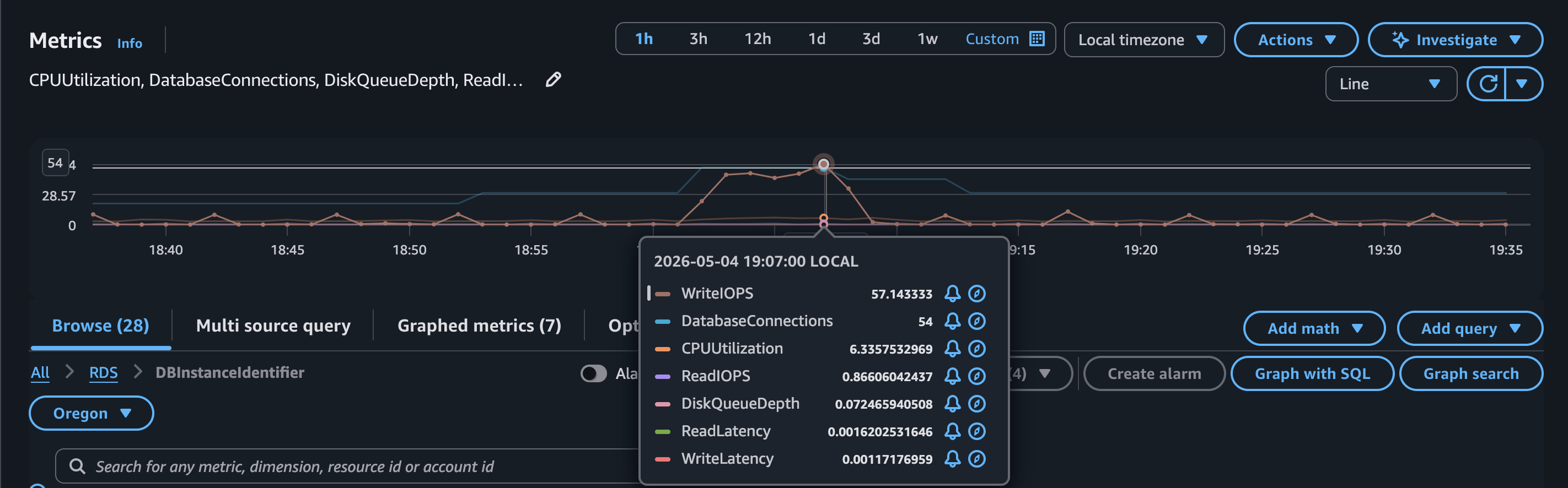
t3.micro) database metrics captured during the same Phase 4 run.
Context (test environment and topology)
This testing was intentionally “small footprint” to validate that Forge scales predictably from minimal infrastructure.
- ECS: 1–2 tasks per service (Phase 4 scaled to 2 tasks); small task sizing (0.25 vCPU class, 512 MiB)
- Database: small baseline RDS instance (
t3.micro) - Load generator: k6 running on an EC2 instance in the same VPC (minimizes network variance and avoids internet egress)
This is not a “final production architecture”; it is a controlled baseline to validate repeatability and scaling behaviour.
Prerequisites (what you need to reproduce)
- k6 client host: EC2 instance in the same VPC as the ECS services and database
- WAF configuration: tuned to permit high request rates from the k6 host (notably 100,000 requests/IP)
- Stable seeded data: baseline mix is auth-heavy and can be sensitive to shared identity/test-user concurrency
Tuning and feedback (what we changed and why it mattered)
The overall story of tuning in these phases is that we addressed connection lifecycle and pool sizing so the system would remain stable under higher concurrency.
- REST client connection lifecycle
- We observed connection churn symptoms on internal calls at 100 VUs.
- Mitigation was to bound reuse by setting a REST client connection TTL (documented in the Phase 4, 100 VUs envelope):
performance/phase_4/ECS_NATIVE_BASELINE_MIX_100VU_LOAD3M_ENVELOPE.md
- Database connection pool tuning
- At 200 VUs, we tuned DB pool sizing and then reduced pool sizing again once we scaled out to two tasks per service
(the steady-state envelope Runs 3–5 use
max-size=14,min-size=5). - This helped keep queueing and resource contention under control as concurrency increased.
- At 200 VUs, we tuned DB pool sizing and then reduced pool sizing again once we scaled out to two tasks per service
(the steady-state envelope Runs 3–5 use
Overview (test plan and where to find results)
The test plan is the canonical reference for phases, success criteria, and methodology:
- Test plan:
performance/PERF_TEST_PLAN.md
Phase write-ups (recommended reading order):
- Phase 1 local baseline (internal reference):
performance/phase_1/LOCAL_JVM_BASELINE_MIX_50VU_LOAD3M_SUMMARY.md - Phase 1 ECS baseline narrative:
performance/phase_1/ECS_NATIVE_BASELINE_MIX_50VU_LOAD3M_SUMMARY.md - Phase 2 baseline envelope (math + operating point):
performance/phase_2/ECS_NATIVE_BASELINE_MIX_50VU_LOAD3M_ENVELOPE.md - Phase 4 scaling envelopes:
Raw artifacts (k6 outputs, CSV extracts, screenshots) are stored adjacent to their phase envelopes inside each phase folder.
Phase 4 focus (200 VUs, Runs 3–5)
Phase 4 at 200 VUs is the first materially production-like scaling dataset, in the sense that it uses true concurrent multi-user behaviour and repeatable steady-state runs after tuning and horizontal scaling.
From the Phase 4 envelope:
- Steady-state throughput (Runs 3–5): ~222 req/s (spread under 0.3% run-to-run)
- Latency: aggregate HTTP medians in the ~6–7 ms range; p95 in the ~360–420 ms range; p99 in the ~850–900 ms range
- Errors: ~0% (only isolated transient failures across ~379k requests)
The key scaling moment is the step from 1 task → 2 tasks per service:
- Throughput: ~190 req/s (single task) → ~222 req/s (two tasks) (+17%)
- Tail improvement: latency distribution improves materially after scaling in this mixed scenario
Interpretation:
- The Forge services scale well horizontally at this footprint.
- The auth-heavy nature of the scenario means overall tails are shaped by authentication latency.
- Internal endpoints (e.g., actor fetch, uploads) recover strongly after scaling and do not appear to be the limiting factor.
External dependencies (what limits the observed tails)
This test’s “baseline mix” scenario is intentionally auth-heavy and exercises external identity operations. As a result:
- AWS Cognito is a dominant contributor to observed tail latency for login/register in the aggregate
http_req_durationmetrics. - The workload also includes AWS-managed infrastructure components (ALB/WAF/ECS/RDS), which can contribute variance at higher load, but in these runs we did not observe systemic infrastructure instability.
This is why “system-wide p95/p99” in the mixed scenario should be interpreted as end-to-end including auth, not purely internal service compute.
Future work and why we stopped at 200 VUs
Phase 4’s objective was not simply to maximize VU count. It was to identify whether saturation signals appeared and whether the platform recovered predictably under horizontal scaling. The 200 VU runs achieved both outcomes.
We stopped at 200 VUs because we had already demonstrated the properties we needed for this stage:
- Repeatable envelopes at baseline and at scale
- A clean scaling step via horizontal task scaling
- Predictable tail behaviour dominated by known external dependencies
The next steps depend on the audience and intended production shape:
- Go higher (300–500+ VUs) to extend the scaling curve and identify the next saturation point under the scaled topology.
- Isolate auth (e.g., token reuse / auth-bypassed scenarios) to quantify internal service capacity without Cognito in the loop.
- Match a target production profile (task sizing, DB class, multi-AZ, caching, domain services enabled) and re-run the same plan to produce a customer-facing capacity model.
Glossary (reading the metrics)
- VU (virtual user): concurrent k6 user executing the scenario.
- RPS / req/s: aggregate HTTP request rate across the entire scenario mix (
http_reqs/ second). - p95 / p99: high-percentile latency; in this work we treat them as bands across repeat runs rather than a pooled percentile.